引言
本章聚焦AI驱动的图像生成工具,重点介绍业界领先的Midjourney平台。通过深入浅出地解析Midjourney官方文档,我们将带领读者快速掌握AI文本生成图像的基本概念和操作技巧。同时,我们还将简要介绍Stable Diffusion和DALL-E 3等其他主流工具,并探讨AI图像生成技术带来的伦理挑战和未来趋势。本章旨在为读者开启AI辅助设计的大门,助力他们在创意设计的新纪元中把握先机。
1. MIDJOURNEY官方文档节选翻译
(官方文档链接:https://docs.midjourney.com/docs)
1.1 入门指南(Getting Started)
1.1.1 网页版快速入门
观看以下视频,快速了解 midjourney.com 的使用,然后按照下面的指南创建您的第一批图像!
在Midjourney.com上创建图像
1. 使用想象栏创建图像
在网站的大多数页面顶部,您会看到想象栏。要开始创建图像,只需在栏中输入提示并按回车键。

一旦您的图像开始生成,您可以在"创建"标签页中找到它们。点击该标签页查看您的结果。
2. 创建变体
在"创建"标签页中,您可以看到所有已生成的图像。点击一个图像可以打开灯箱视图。一旦您找到喜欢的图像,就可以使用变体功能创建新版本。

灯箱还提供了其他工具来帮助您优化和实验图像。您可以了解更多关于放大、重新构图和重新绘制等功能的信息。
3. 更改设置
想象栏中的设置按钮允许您为所有提示设置默认参数。您可以调整图像的宽高比、风格化程度和多样性,或调整生成速度和隐私设置。

4. 在提示中使用图像
Midjourney可以使用现有图像作为灵感来创建全新的图像。您可以将喜欢的图像拖放到想象栏中,有三种不同的使用方式:

要深入了解如何使用参考图像,请查看我们的在Web上使用图像页面。
5. 保存和管理图像
如果您准备下载图像或想要过滤或组织它们,请访问归档标签页。
无论在哪里看到 按钮,您都可以点击保存单个图像。您也可以通过在网格外点击并拖动进行选择来批量下载图像。

您可以在这里找到更多关于归档页面的过滤器和其他选项的信息。
6. 与他人协作创作
没有什么比与他人一起创作图像更能激发创意能量了!在 聊天标签页,您可以找到(或创建!)与其他用户一起工作的共享空间。
需要一些灵感?每天查看每日主题聊天室,获取新的提示主题!在那里观察其他用户如何创造性地融入当日主题,或与他们一起创作。
1.1.2 Discord版快速入门
通过Discord中的Midjourney机器人,您可以在几秒钟内使用简单的文本提示生成令人惊叹的图像。直接在Discord中工作,无需专门的硬件或软件。
- 不要做一个混蛋。
- 不要使用我们的工具制作可能引起争议、不安或引起戏剧性的图像。这包括血腥和成人内容。
- 尊重他人和团队。
1. 登录Discord
通过网络浏览器、移动应用程序或桌面应用程序访问Discord中的Midjourney机器人。在加入Midjourney Discord服务器之前,请确保您有一个经过验证的Discord账户。
按照以下指南创建或验证您的Discord账户:
创建Discord账户
验证Discord账户
2. 订阅Midjourney计划
要开始使用Midjourney生成图像,您需要订阅一个计划。
- 访问 Midjourney.com。
- 使用您的经过验证的Discord账户登录。
- 选择适合您需求的订阅计划。
有关定价和每个等级可用功能的信息,请访问订阅计划。

3. 加入Discord上的Midjourney服务器
要开始与Midjourney机器人互动,请加入Midjourney服务器
- 打开Discord并找到左侧侧边栏中的服务器列表。
- 按服务器列表底部的
+按钮。 - 在弹出窗口中,点击
加入服务器按钮。 - 粘贴或输入以下URL:http://discord.gg/midjourney 并按
加入。
要了解更多信息,了解更多关于Discord服务器的信息。
4. 进入任何 #general 或 #newbie 频道
加入Discord上的Midjourney服务器后,您会在侧边栏中看到几个频道列表。
在Midjourney服务器上,找到并选择任何标记为 general-# 或 newbie-#
的频道。这些频道是为初学者开始使用Midjourney机器人而设计的。Midjourney机器人不会在其他频道中生成图像。
在其他服务器上,您可以在任何邀请了Midjourney机器人的Discord服务器上生成图像。查看您所在服务器的说明,了解在哪里使用机器人。
5. 使用 /imagine 命令
关于Discord命令
在Discord上通过命令与Midjourney机器人互动。命令用于创建图像、更改默认设置、监控用户信息和执行其他有用的任务。/imagine
命令从简短的文本描述(称为提示)生成独特的图像。了解更多关于提示的信息
如何使用 /imagine
- 在消息字段中输入'/imagine prompt:'。您也可以从输入'/'时弹出的可用斜杠命令列表中选择
/imagine命令。 - 在
prompt字段中输入您想要创建的图像描述。 - 发送您的消息。机器人将解释您的文本提示并开始生成图像。
- 遵守社区指南。无论在哪里使用Midjourney机器人,社区指南都适用。

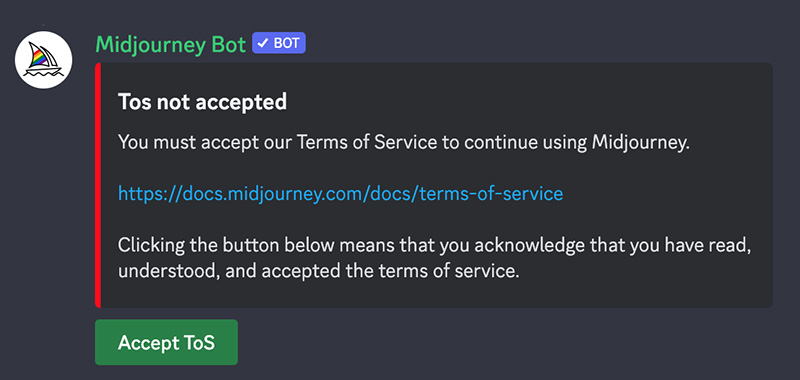
6. 接受服务条款
在生成任何图像之前,Midjourney机器人会提示您接受服务条款。您必须同意这些条款才能继续创建图像。
7. 图像生成过程
提交文本提示后,Midjourney机器人会处理您的请求,在一分钟内创建四个独特的图像选项。此过程利用先进的图形处理单元(GPU),每次图像生成都会计入您Midjourney订阅中包含的GPU时间。要监控您可用的GPU时间(剩余快速时间),请使用
/info 命令。
8. 选择图像或创建变体
一旦生成了初始图像网格,图像网格下方会出现两排按钮。
- U1 U2 U3 U4 按钮:选择单个图像
- 🔄 按钮:重新运行或重新生成作业
- V1 V2 V3 V4 按钮:创建所选图像的变体
9. 增强或修改您的图像
单独选出一个图像后,会出现一组扩展的选项。
- 🪄 Vary (Strong) / 🪄 Vary (Subtle):创建所选图像的强烈或微妙变体
- 🔍 Zoom Out 2x / 🔍 Zoom Out 1.5x / 🔍 Custom Zoom:放大您的图像
- ⬅️ ➡️ ⬆️ ⬇️:平移按钮允许您在选定方向上扩展图像的画布
- ❤️ Favorite:标记您最喜欢的图像
- Web ↗️:在 midjourney.com 上的画廊中打开图像
10. 保存您的图像
点击图像以全尺寸打开,然后右键单击并选择 保存图像。在移动设备上,长按图像,然后点击右上角的下载图标。
所有图像都可以立即在 midjourney.com/imagine 上查看
后续步骤
直接与Midjourney机器人通信
在Midjourney服务器上与其他用户一起工作时遇到困难?您可以在直接消息中一对一与Midjourney机器人互动。在直接消息中创建的图像仍然受内容和审核规则的约束,并且在Midjourney网站上可见。
了解更多关于提示
了解如何编写有效和创意的提示,
探索艺术媒介、位置和时期的描述如何改变图像。
混合您自己的图像
学习如何使用 /blend 命令上传和混合您自己的图像。
Midjourney机器人帮助
需要帮助或有问题?尝试这些命令:
/help 显示有关Midjourney机器人的有用信息和提示。
/ask 提供关于Midjourney机器人的问题答案。

您也可以访问Midjourney Discord上的#支持频道获取额外帮助。
账单和订阅查询
关于账单和订阅问题,请访问 help.midjourney.com。
1.1.3 社区指南
简介
Midjourney是一个默认开放的社区。为了保持平台对最广泛用户群的可访问性和友好性,内容必须是"适合工作场所"(SFW)的。
我们的四个主要规则
- 友善并互相尊重
- 仅限SFW内容
- 谨慎分享您的创作
- 不允许未经授权的自动化和第三方应用
感谢您帮助我们使Midjourney成为一个安全、欢迎所有人的空间。
如果您看到有人违反这些指南,可以在这里报告。
请以喜悦、好奇、负责任和尊重的态度使用这些令人惊叹的能力。
详细规则
-
友善并互相尊重
- 对他人和工作人员友善和尊重。不会容忍任何形式的暴力行为、骚扰或煽动。
- 不要创建本质上不尊重、侮辱或以其他方式滥用的图像或使用文本提示。
- 不要创建或使用真实人物(无论是否著名)的图像,这些图像可能被用于骚扰、虐待、诽谤或以其他方式伤害。
- 尊重他人的权利。不要试图查找他人的私人信息。不要上传他人的私人信息。
-
仅限SFW内容
- 不要创建或尝试创建血腥或成人内容。避免制作视觉上令人震惊或令人不安的内容。
- 什么被视为血腥? 血腥包括人类或动物的分离身体部位图像、食人、血液、暴力(例如,射击或炸死某人的图像)、肢解的尸体、断肢、瘟疫等。
- 什么是NSFW或成人内容? 避免裸体、性器官、对此类事物的固定关注、色情图像、恋物癖、淋浴中的人、坐在马桶上的人等。
- 不要以任何方式创建或尝试创建将儿童或未成年人性化的内容。这包括真实图像和生成的图像。不要生成、上传、分享或尝试分发描绘、促进或试图正常化儿童性虐待的内容。
- 不要创建其他令人反感的内容。其他事物可能被视为令人反感或滥用,因为它们可能被视为种族主义、同性恋恐惧症、令人不安或以某种方式贬低某个社区。这包括对名人或公众人物的冒犯性或煽动性图像。
-
谨慎分享您的创作
- 未经许可,不要公开重新发布他人的作品。
- 分享时要谨慎。在Midjourney社区之外分享您的创作是可以的,但请考虑其他人可能如何看待您的内容。
- 不要生成图像以传播错误信息或虚假信息。
- 不要为政治竞选生成图像或试图影响选举结果。
- 不要生成图像来尝试或实际欺骗或欺诈任何人。
- 不要故意误导生成图像的接收者有关其性质或来源。
-
不允许未经授权的自动化和第三方应用
- 为了保持所有用户的最高质量体验,Midjourney账户设计为个人使用,每个用户只能维护一个账户。
- 除了少数明确授予的例外情况,Midjourney不提供API,也不提供第三方应用程序或脚本,根据我们的服务条款,严格禁止自动化与Midjourney服务的交互。不遵守这些规则的账户可能会被封锁。
- 您不得转售或重新分发Midjourney服务或对服务的访问(这包括共享您的账户)。
审核政策说明
- Midjourney会自动阻止一些文本和图像输入。输入未被自动阻止并不一定意味着它是允许的。
- 违反服务条款的用户可能会被社区版主警告、暂时禁止使用服务或被永久封禁。
- 如果您看到其他人的内容违反规则,请举报。
总体政策说明
- 上述规则适用于所有内容,包括在私人服务器上制作的图像、删除/隐藏的图像、使用隐身模式、与Midjourney机器人的直接消息以及Midjourney网站。
- 违反这些规则可能导致被禁止使用我们的服务。
- Midjourney既是产品也是社区。我们可能会分别撤销您对社区的访问权限和对产品的访问权限。
- 随着Midjourney社区的发展,内容指南会不断审查和可能修改。
- 不要生成涉及非法活动的图像或将涉及非法活动的图像上传到我们的服务器,或者上传本身可能是非法的内容。
- 这不是一个详尽的列表。我们可能会对违反这些指南精神的用户采取行动,即使他们的行为没有被明确禁止。
- 我们是一个小团队,努力平衡社区中最广泛用户的需求。我们的决策过程不是民主的,但我们非常重视对审核的反馈。
- 最重要的是,玩得开心!
自我监管和报告
有时,提示可能会无意中产生不适合工作场所的内容。请通过使用❌表情反应或右键单击选择应用程序然后点击"取消作业"来自我监管这些图像以删除图像。
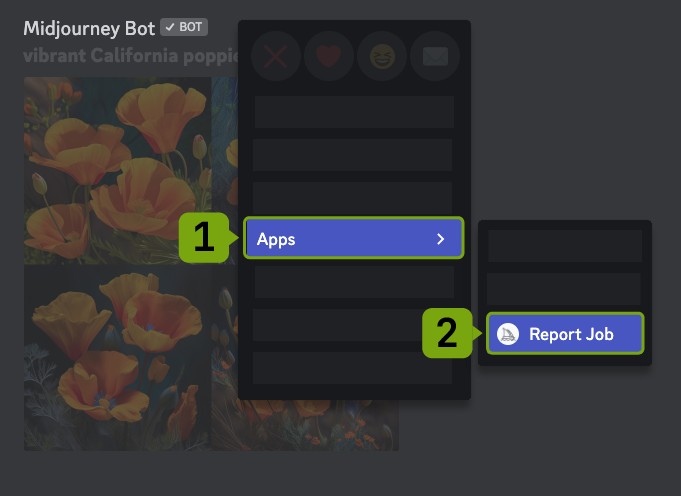
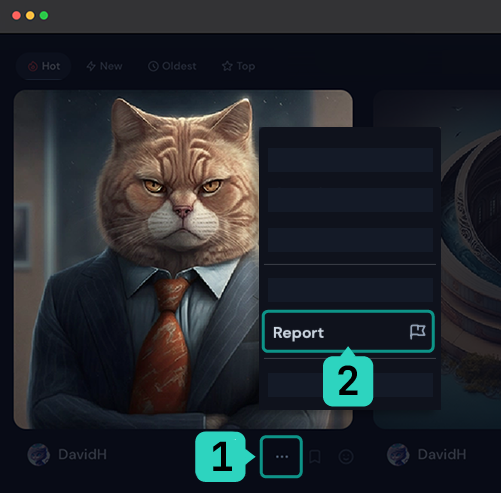
用户可以通过在Discord中右键单击选择应用程序然后点击"报告作业",或在网站上通过选择图像下的"..."然后点击"报告"来标记任何图像以供版主审核。
在Discord中报告图像
在网站上报告图像
1.2 基础概念与操作
1.2.1 提示词(Prompts)
提示词是一个简短的文本短语,Midjourney机器人会解释这个短语来生成图像。Midjourney机器人将提示中的单词和短语分解成更小的部分,称为标记,这些标记会与其训练数据进行比较,然后用于生成图像。精心制作的提示可以帮助创建独特和令人兴奋的图像。
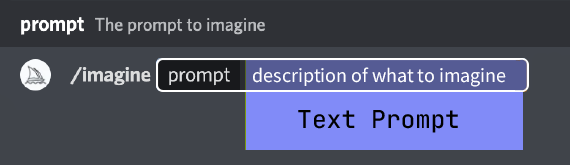
基本提示
基本提示可以简单到只有一个单词、短语或表情符号 😊。
提示技巧!
Midjourney机器人最适合处理描述您想看到的简单、简短的短语。避免使用长列表的请求和指令。不要使用:"给我展示一张很多加州罂粟花盛开的图片,让它们明亮、充满活力的橙色,并以彩色铅笔的插图风格绘制",而应该尝试:"用彩色铅笔画的明亮橙色加州罂粟花"
高级提示
更高级的提示可以包含一个或多个图像URL、多个文本短语和一个或多个参数

文本提示
您想生成的图像的文本描述。请参阅下面的提示信息和技巧。编写得好的提示有助于生成令人惊叹的图像。
提示注意事项
词语选择
词语选择很重要。在许多情况下,更具体的同义词效果更好。比如用微小、巨大、庞大、巨型或浩瀚来替代大。
复数词和集合名词
复数词会留下很多不确定性。尝试使用特定数字。"三只猫"比"猫"更具体。集合名词也有效,比如用"一群鸟"代替"鸟"。
专注于您想要的内容
最好描述您想要的内容,而不是您不想要的内容。如果您要求一个"没有蛋糕"的派对,您的图像可能会包含一个蛋糕。要确保某个物体不在最终图像中,请尝试使用 --no
参数进行高级提示。
提示长度和细节
提示可以很简单。单个词或表情符号就可以。然而,简短的提示依赖于Midjourney的默认风格,允许它创造性地填充任何未指定的细节。在您的提示中包含任何对您重要的元素。细节越少意味着更多的多样性,但控制力更少。
尝试清楚地说明对您来说重要的任何上下文或细节。考虑以下几点:
- 主题: 人、动物、角色、位置、物体
- 媒介: 照片、绘画、插图、雕塑、涂鸦、挂毯
- 环境: 室内、室外、月球上、水下、在城市中
- 照明: 柔和、环境、阴天、霓虹灯、摄影棚灯光
- 颜色: 生动的、柔和的、明亮的、单色的、丰富多彩的、黑白的、柔和的
- 情绪: 平静的、安静的、喧闹的、充满活力的
- 构图: 肖像、头部特写、特写、鸟瞰图
1.2.2 探索提示词(Explore Prompting)
即使是简短的单词提示也能以Midjourney的默认风格产生美丽的图像,但通过结合艺术媒介、历史时期、地点等概念,您可以创造出更有趣的个性化结果。
选择一种媒介
拿出颜料、蜡笔、刮画板、印刷机、亮片、墨水和彩纸。创造风格化图像的最佳方式之一是指定一种艺术媒介。
提示示例:/imagine prompt <任何艺术风格> 风格的猫














更加具体
更精确的词语和短语将有助于创造具有恰当外观和感觉的图像。
提示示例:/imagine prompt <风格> 猫的素描





时间旅行
不同的时代有不同的视觉风格。
提示示例:/imagine prompt <时间段> 风格的猫的插画















表达情感
使用情感词语给角色赋予个性。
提示示例:/imagine prompt <情感> 的猫





丰富多彩
色彩的全光谱可能性。
提示示例:/imagine prompt <颜色词> 的猫















环境探索
不同的环境可以营造独特的氛围。
提示示例:/imagine prompt <地点> 中的猫










1.2.3 变体(Variations)
使用图像网格下方的 V1 V2 V3 V4 按钮,或使用放大图像下方的
Vary (Strong) 和 Vary (Subtle) 按钮来生成该图像的不同版本。
想在制作变体时更改提示词吗?在设置中启用 Remix Mode。在这里了解更多关于使用 Remix
Mode 以及它如何与您的变体设置交互的信息。
变体示例
当使用 Midjourney 版本 5 或 6,或 Niji 版本 5 或 6 时,您可以在高变化和低变化模式之间选择。
默认的 🎨 High Variation Mode
将生成在构图、元素数量、颜色和细节类型上与原图有所不同的新图像。要使用高变化模式,请在设置中选择它,然后点击网格下方的 V 按钮,或点击放大图像下方的 🪄 Vary (Strong) 按钮。
🎨 Low Variation Mode
将生成保留原图构图和颜色的新图像,但对图像细节进行微妙的更改。要使用低变化模式,请在 /settings 中选择它,然后点击对应于您想要变化的图像的
V 按钮,或点击放大图像下方的 🪄 Vary (Subtle) 按钮。
提示示例:/imagine prompt a cute robot holding flowers
原始放大图像

使用 🪄Vary (Subtle) 的图像网格

使用 🪄Vary (Strong) 的图像网格

提示示例:/imagine prompt a bird watching a butterfly
原始放大图像

使用 🪄Vary (Subtle) 的图像网格

使用 🪄Vary (Strong) 的图像网格

1.2.4 放大器(Upscalers)
当前的 Midjourney 和 Niji 模型版本生成 1024 x 1024 像素的图像网格。使用每个图像网格下方的
U1 U2 U3 U4 按钮将您选择的图像从网格中分离出来。然后,您可以使用
Upscale (Creative) 或 Upscale (Subtle) 工具来增加图像的大小。
Upscale (Subtle) 选项会将您的图像尺寸加倍,并保持细节与原图非常相似。Upscale (Creative)
也会将您的图像尺寸加倍,但会向图像添加新的细节。尝试每种放大器选项,找到最适合您图像风格的一种。
Upscale工具使用您订阅的 GPU 分钟。放大可能会使用多达两倍于生成初始图像网格的 GPU 分钟。Upscale工具与 --tile 参数不兼容。
如何使用放大工具
1. 生成图像
使用 /imagine 命令创建图像。

2. 选择图像
使用 U 按钮将您选择的图像从网格中分离出来。
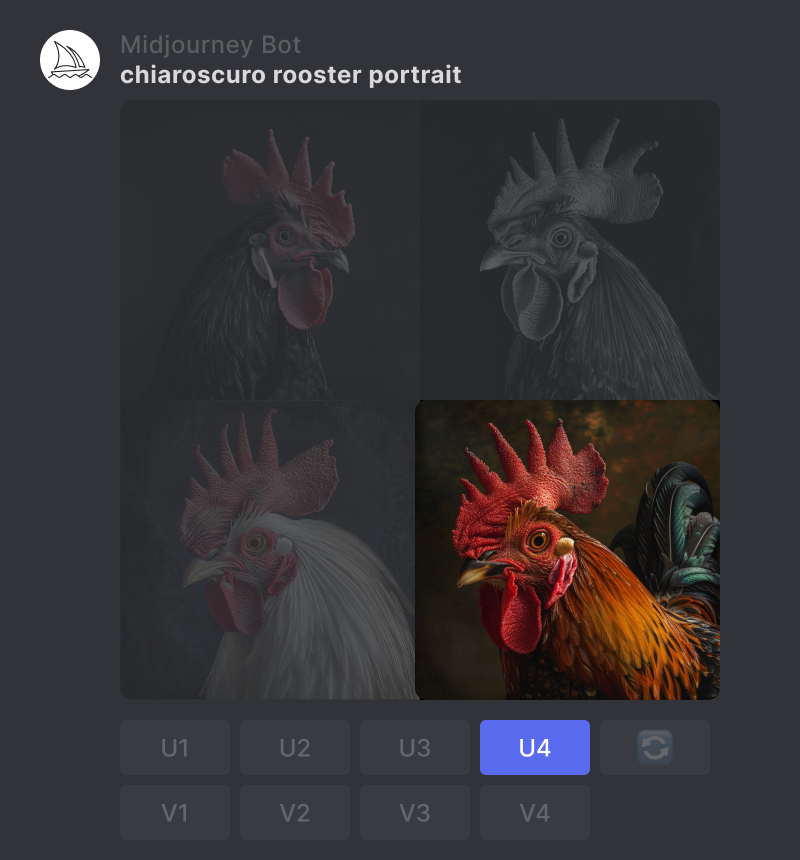
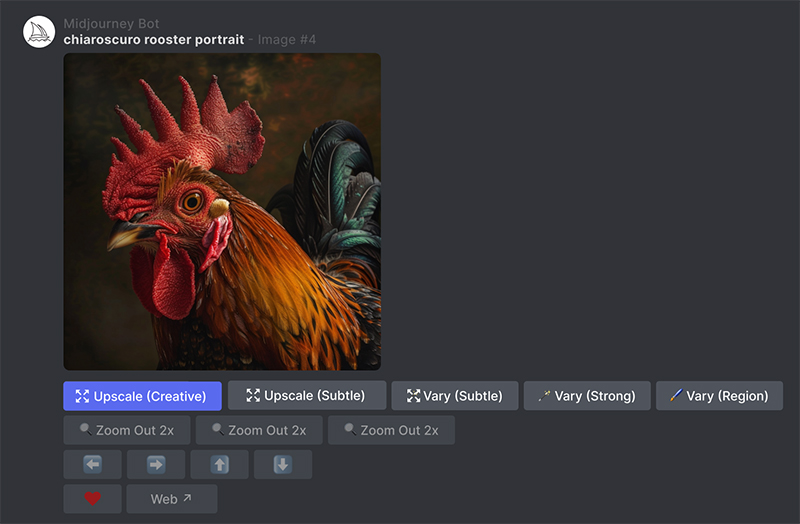
3. 选择放大
点击 Upscale (Subtle) 或 Upscale (Creative) 按钮来放大您的图像。放大器将使您的图像尺寸加倍至 2048 x
2048 像素。
放大对比
提示:chiaroscuro rooster portrait
原始 1024 x 1024 像素图像。

原始图像的细节
原始图像

放大到 2048 x 2048 像素后

放大对比
提示:1960s pop-art acrylic painting of a stream running through a redwood forest
原始图像

Subtle 放大

Creative 放大

原始图像的细节

Subtle 放大的细节

Creative 放大的细节

通过使用 /show 命令刷新在新放大器发布之前生成的作业。刷新后的作业下方将出现与该图像兼容的所有放大器的按钮。
旧版放大器
早期的 Midjourney 模型版本生成较低分辨率图像的网格。您可以在这些使用早期 Midjourney 模型创建的图像上使用旧版 Midjourney 放大器来增加尺寸并添加额外的细节。有多个旧版放大模型可用于放大使用早期 Midjourney 模型创建的图像。使用旧版放大器会消耗您订阅的 GPU 分钟。
1.2.5 区域变化(Vary Region)
使用Midjourney区域变化编辑器来选择和重新生成已放大图像的特定部分。
Vary (Region)按钮会在Midjourney图像被放大后出现。- 区域变化的结果受原始图像内容和您选择的区域的引导。
Vary (Region)与 Midjourney模型版本V5,V6,niji 5, 和niji 6兼容。
如何使用区域变化
1. 生成图像
使用 /imagine 命令创建图像。

2. 放大图像
使用U按钮放大您选择的图像。

3. 选择区域变化
点击 🖌️ Vary (Region) 按钮打开编辑界面。

4. 选择要重新生成的区域
- 在编辑器左下角选择自由手绘或矩形选择工具。
- 选择您想要重新生成的图像区域。
- 选择的大小会影响您的结果。较大的选择给Midjourney机器人更多空间来生成新的创意细节。较小的选择会导致更小、更微妙的变化。
注意:您无法编辑现有的选择,但可以使用右上角的撤销按钮撤销多个步骤。
- 选择的大小会影响您的结果。较大的选择给Midjourney机器人更多空间来生成新的创意细节。较小的选择会导致更小、更微妙的变化。

5. 提交您的作业
点击 Submit →
按钮将您的请求发送给Midjourney机器人。现在可以关闭区域变化编辑器,您可以在作业处理时返回Discord。
注意 您可以多次使用放大图像下方的 🖌️ Vary (Region)
按钮来尝试不同的选择。您之前的选择将被保留。您可以继续添加到这个现有的选择,或使用 undo 按钮清除您的选择。

6. 查看您的结果
Midjourney机器人将处理您的作业,并在您选择的区域内生成一个新的变体图像网格。

区域变化示例
放大的图像

提示:彩色糖果胸针
选择

结果

放大的图像

提示:房子的建筑图纸
选择

结果

技术细节
使用区域变化(Vary Region)生成的作业将遵守以下参数:
--chaos
--fast
--iw
--no
--stylize
--relax
--style
--version
--video
--weird
1.2.6 区域变化与重组(Vary Region + Remix)
结合重组模式和Midjourney区域变化编辑器,使用新的或修改的提示来选择和重新生成已放大图像的特定部分。
Vary (Region)按钮会在Midjourney图像被放大后出现。- 区域变化结果受原始图像内容、您选择的区域以及使用的修改提示的引导。
Vary (Region)与 Midjourney模型版本V5,V6,niji 5, 和niji 6兼容。
如何将重组模式与区域变化一起使用
1. 启用重组模式
使用 /settings 命令并从弹出窗口中选择 🎛️ Remix。
2. 生成图像
使用 /imagine 命令创建图像。

3. 放大图像
使用U按钮放大您选择的图像。
4. 选择区域变化
点击 🖌️ Vary (Region) 按钮打开编辑界面。
5. 选择要重新生成的区域
- 在编辑器左下角选择自由手绘或矩形选择工具。
- 选择您想要重新生成的图像区域。
- 选择的大小会影响您的结果。较大的选择给Midjourney机器人更多空间来生成新的创意细节。较小的选择会导致更小、更微妙的变化。
注意:您无法编辑现有的选择,但可以使用右上角的撤销按钮撤销多个步骤。
- 选择的大小会影响您的结果。较大的选择给Midjourney机器人更多空间来生成新的创意细节。较小的选择会导致更小、更微妙的变化。
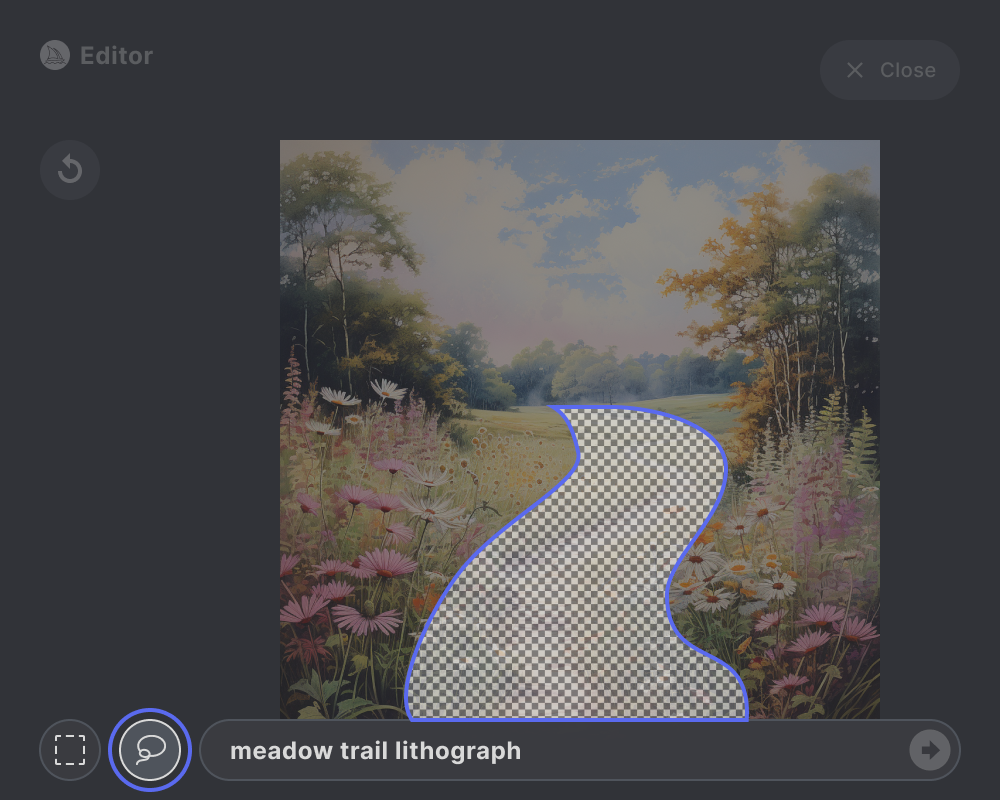
6. 修改您的提示
使用更新的提示描述您想在选定区域生成的内容。您修改后的提示应该集中在您想要引入或改变的细节上。

7. 提交您的作业
点击 Submit →
按钮将您的请求发送给Midjourney机器人。现在可以关闭区域变化编辑器,您可以在作业处理时返回Discord。
注意 您可以多次使用放大图像下方的编辑器按钮来尝试不同的选择和提示。

8. 查看您的结果
Midjourney机器人将处理您的作业,并使用您原始图像的信息和新提示的指导生成一个新的图像网格。
新的图像网格

原始vs变化比较

8. 再次放大和区域变化
您可以放大其中一个新图像,并再次使用区域变化编辑器来继续优化您的图像。
选择

结果

更新的提示: 热气球石版画
结果

更新的提示: 草地中的城堡石版画
区域变化 + 重组提示技巧
-
选择 您的选择大小会影响结果。较大的选择为Midjourney机器人提供更多上下文信息,这可以改善新添加元素的缩放和上下文。但选择太多可能会导致新生成的元素与您希望保留的原始图像部分混合或替换。
-
提示 在使用区域变化 + 重组模式时,尝试如何修改您的提示。提示应该集中在您想在选定区域发生的事情上。Midjourney机器人在生成选定区域时也会考虑现有图像,所以更短、更集中的提示通常更有效。Midjourney提示不应该是对话式的。不要说"请将草地小径改成美丽的溪流",而应该直接说"草地溪流"。
-
小步骤工作 如果您想改变图像的多个部分,一次处理一个部分。这样,您可以为每个部分创建一个集中的提示。
区域变化 + 重组示例
原始图像

提示:水彩戴墨镜的鳄鱼
选择

更新的提示:水彩戴绿色墨镜的鳄鱼
结果

更新的提示:水彩戴绿色墨镜的鳄鱼
原始图像

提示:刮画苹果树枝
选择

更新的提示:彩虹刮画苹果树枝
结果

更新的提示:彩虹刮画苹果树枝
技术细节
使用区域变化(Vary Region)+ 重组模式生成的作业将遵守以下参数:
--chaos
--fast
--iw
--no
--stylize
--relax
--style
--version
--video
--weird
1.2.7 版本(Version)
Midjourney定期推出新的模型版本,以提高连贯性、效率、质量和风格。您可以使用 --version 或 --v 参数或使用 /settings 命令并选择您喜欢的模型版本来切换模型版本。不同的模型在生成不同类型的图像方面表现出色。
--version接受值 1, 2, 3, 4, 5, 5.0, 5.1, 5.2, 6, 和 6.1。--version可以缩写为--v。--v 6.1是最新的且当前默认的模型。
模型版本 6.1
版本6.1于2024年7月30日发布,成为新的默认模型。它生成更加连贯的图像,具有更精确的细节和纹理,并且生成图像的速度比版本6快约25%。


模型版本 6
Midjourney 模型版本 6 增强了对长输入的提示准确性,改进了连贯性和知识,并提升了图像提示和重组功能。
Midjourney 模型版本 6 于 2023 年 12 月 20 日发布,从 2024 年 2 月 14 日至 7 月 30 日期间是默认模型。


Niji 模型 6
Niji 模型是 Midjourney 与 Spellbrush 合作的成果,专门调教用于生成动漫和插图风格,具有更多的动漫、动漫风格和动漫美学知识。它在动态和动作镜头以及以角色为中心的构图方面表现出色。
要使用此模型,请在提示的末尾添加 --niji 6 参数,或使用 /settings 命令并选择 🌈 Niji version 6


Niji 6 vs. Midjourney 版本 6
--v 6

vibrant California poppies --v 6
--niji 6

vibrant California poppies --niji 6
--v 6

fruit salad tree --v 6
--niji 6

fruit salad tree --v 6 --style raw
如何切换模型
使用版本参数
使用 --version 或 --v 参数来更改模型版本。例如,--v 5.2 使用版本 5.2,或
--niji 6 使用 Niji 版本 6。

使用 Discord 设置命令
输入 /settings 并从下拉列表中选择您喜欢的版本。
想要了解更多关于 Midjourney 旧模型的信息?查看 遗留模型版本页面。
网站设置
您可以使用想象栏中的设置按钮设置默认版本:

从下拉菜单中选择您喜欢的版本。您的图像将使用该版本生成,除非您在单个提示中使用 --version 或 --v 参数指定不同的值。
1.3 命令、参数和工具(Commands, Parameters, and Tools)
Midjourney提供了丰富的命令、参数和工具来帮助您更好地控制图像生成过程。要了解更多详细信息,请访问我们的命令和参数专页。
2. 部分其他图像生成工具
2.1 Stable Diffusion:最流行的开源模型
Stable Diffusion作为一种开源的人工智能图像生成技术,在当前市场中展现出独特的优势和潜在挑战。
2.1.1 优势
- 社区驱动的创新生态:Stable Diffusion的开源特性吸引了广泛的开发者参与,推动了技术的快速迭代。例如,ControlNet插件的引入使得用户能够通过条件输入(如姿势关键点、深度图等)精确控制图像生成过程。
- 高度定制化能力:支持多样化的插件和模型,如ComfyUI提供的基于节点的工作流定制,允许用户通过调整模块连接实现不同的输出效果。
- 商业应用的适应性:其灵活性和开源性使企业能够迅速将Stable Diffusion集成到现有工作流程中,适用于内容创作、广告设计或游戏开发等多个领域。
- 高质量图像生成潜力:在精心调校的条件下,能够生成细节丰富的高质量图像。例如,After Detailer插件能够在小图上精修人物的面部、手部和全身细节。
2.1.2 局限
- 硬件要求较高:为实现最佳性能,用户需要配备高性能GPU和充足的内存。
- 操作稳定性问题:特别是在本地部署环境中处理大量或复杂的图像生成任务时,可能面临稳定性挑战。
2.1.3 关键插件及其影响
Stable Diffusion的生态系统因其重要插件而得到进一步增强:
- ControlNet:通过添加条件图片的形式来自定义内容,实现用户期望的精确效果。
- ComfyUI:提供高度模块化的用户界面,简化了用户入门过程,使快速运行第一个图像生成工作流成为可能。
2.2 DALL-E 3
DALL-E 3,作为OpenAI推出的文生图像AI模型,内嵌于chatGPT中,在此简单介绍其优势与局限。
2.2.1 优势
- 卓越的语言理解能力:基于ChatGPT构建,显著提升了自然语言处理能力。
- 简化的用户交互:用户可通过简单描述即可生成精准的提示词,进而转化为图像。
- 细节描绘的精准性:能够准确捕捉并呈现抽象概念和模糊形容词的深层含义。
- 与ChatGPT的无缝集成:极大提升了用户的工作效率和创作体验。
2.2.2 局限
- 图像质量:整体不如Midjourney等竞争对手。
- 空间关系处理:在处理图像中的空间位置关系时可能存在错误。
- 人物细节:在皮肤纹理和表情的真实感上可能略显不足。
2.2.4 应用建议
DALL-E 3在自然语言交互和图像生成的结合方面具有显著优势,但在某些具体的图像质量指标上可能存在局限。用户在选择时应考虑以下因素:
- 如果项目重点在于通过自然语言快速生成图像,DALL-E 3可能是理想选择。
- 对于需要极高图像质量,特别是在人物描绘方面的项目,可能需要考虑Midjourney等替代选项。
- 最终选择应基于具体项目需求、创作目标和个人偏好来决定。
3. AI图像生成的伦理问题和未来趋势
人工智能图像生成技术作为计算机视觉和深度学习领域的前沿发展,正在以前所未有的速度渗透到社会的各个层面。然而,伴随这一技术进步的是一系列复杂的伦理问题、法律挑战以及对未来发展趋势的深远影响。本节将对这些方面进行深入探讨。
3.1 伦理问题
AI图像生成技术的广泛应用引发了多方面的伦理问题,主要包括:
- 隐私保护:AI生成的图像可能涉及个人隐私信息的不当使用或泄露。
- 信息真实性:该技术可能被用于制作和传播虚假或误导性信息。
- 知识产权:在未经授权的情况下使用网络图像作为训练数据,可能引发版权争议。
- 社会偏见:AI生成的图像可能无意中强化现有的社会偏见和刻板印象。
- 滥用风险:技术可能被用于身份伪造或欺诈等非法活动,威胁社会秩序。
3.2 法律挑战
AI图像生成技术的快速发展对现有法律体系提出了新的挑战:
- 版权归属:AI生成图像的知识产权归属问题尚未得到明确界定。
- 责任认定:对于AI生成的不实或有害内容,责任追究机制需要进一步明确。
- 法律更新:现有法律法规需要适应性调整,以应对新技术带来的挑战。
3.3 未来发展趋势
AI图像生成技术的未来发展趋势主要集中在以下几个方面:
- 图像质量提升:技术将朝着生成更高质量、更逼真的图像方向发展。
- 多样性和稳定性:提高生成图像的多样性和生成过程的稳定性。
- 精细控制能力:实现对生成过程更精细、更精准的控制。
- 深度语义理解:加强对图像实体关系的深层次理解。
- 多模态融合:提升跨模态间的转换和生成效果。
- 性能优化:提高采样速度和样本质量。
- 市场细分:向更加标准化、细分化的市场需求方向发展,以满足不同用户群体的需求。
3.4 商业授权策略:
- 对于各类免费用户,不保证其版权与商业应用许可,用户需要自行负责。
- 对于付费用户,根据软件和平台的不同,承诺其版权与部分商业应用许可。
- 对于stable diffusion这样的开源模型,其条款会更复杂一些,并且仍在不断更新中,目前对于SD的核心模型使用,100万美元收入以下的组织和团体是免费的